
Spree: A Live-Updating Web UI for Spark
25 Jul 2015At Hammer Lab, we run various genomic analyses using Spark. Most Spark users follow their applications’ progress via a built-in web UI, which displays tables with information about jobs, stages, tasks, executors, RDDs, and more:
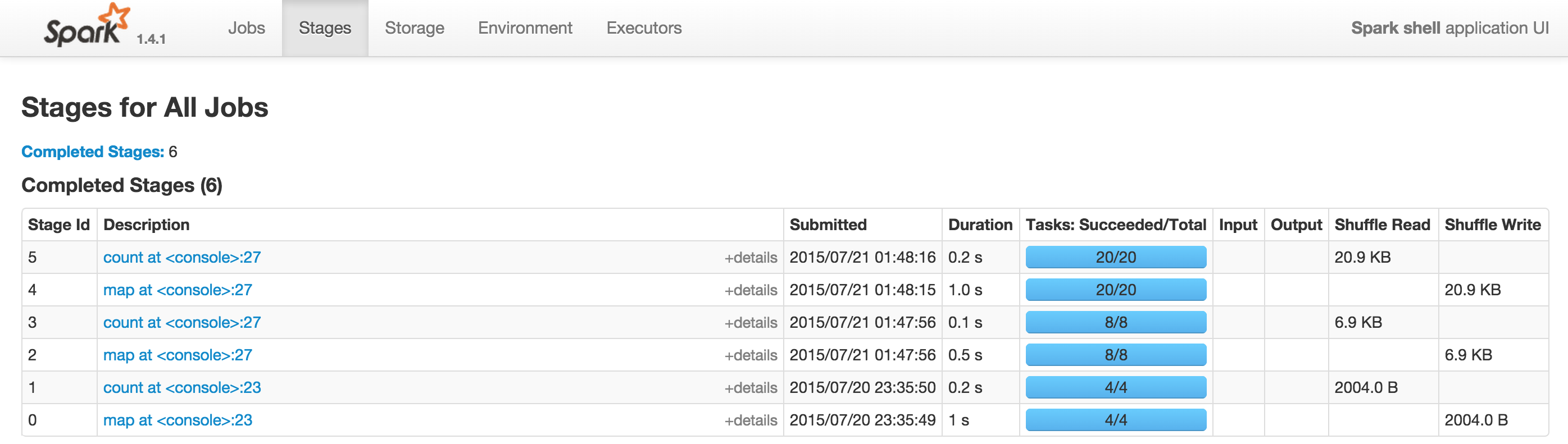
This UI offers a wealth of information and functionality, but serious Spark users often find themselves refreshing its pages hundreds of times a day as they watch long-running jobs plod along.
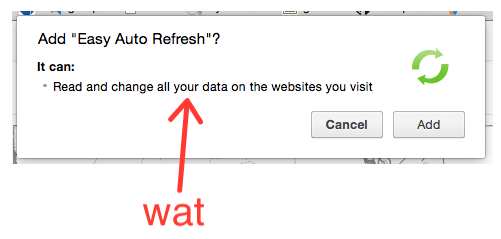
Some even use Chrome extensions like Easy Auto-Refresh to force the page to refresh every, say, two seconds. This mitigates the problem somewhat, but is fairly clumsy and doesn’t provide for a very pleasant user experience; the page spends a significant fraction of its time refreshing and unusable, and the server and browser are made to do lots of redundant work, slowing everything down.
Enter: Spree
This led us to develop Spree, a live-updating web UI for Spark:
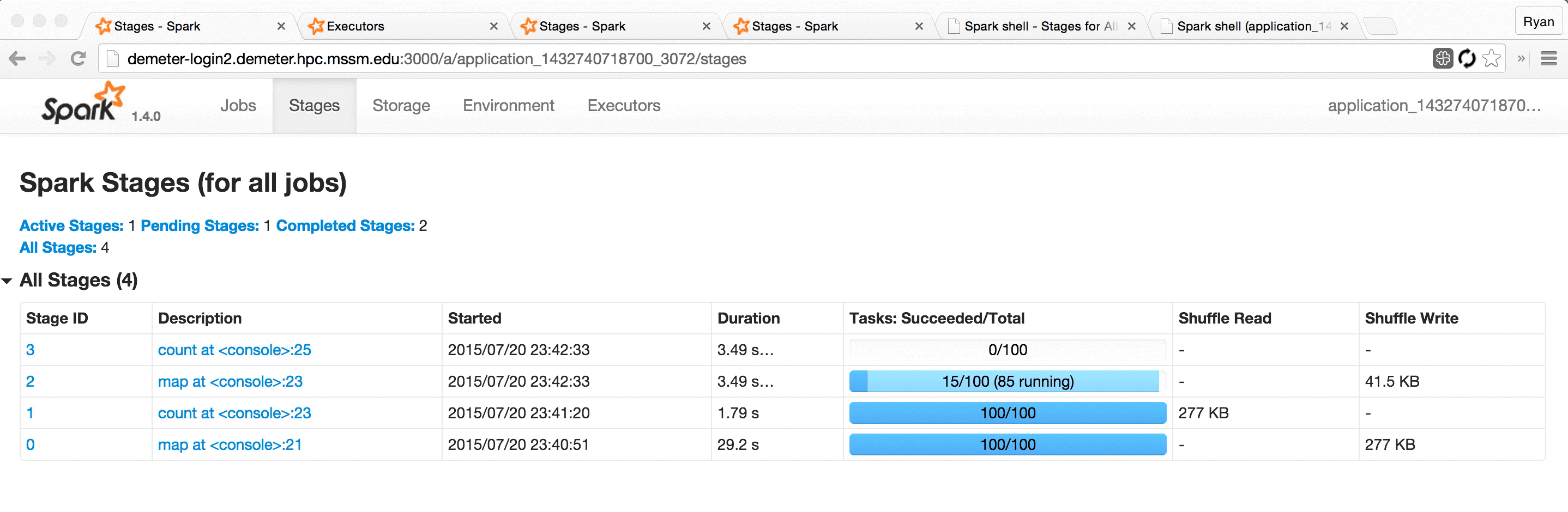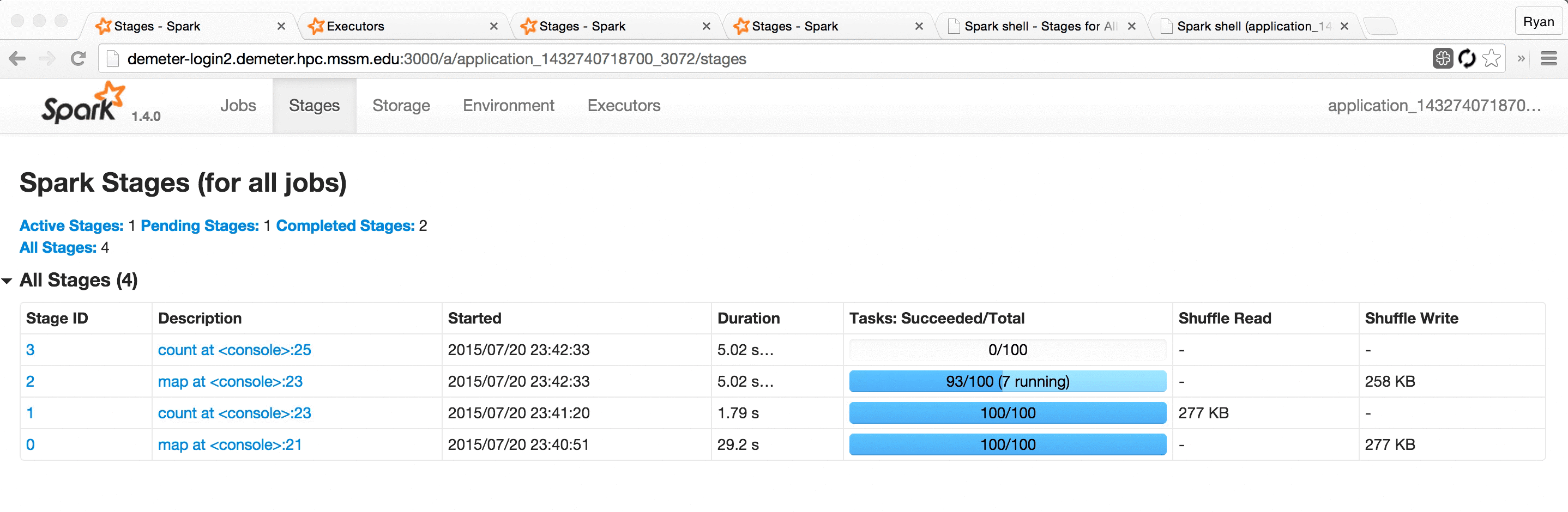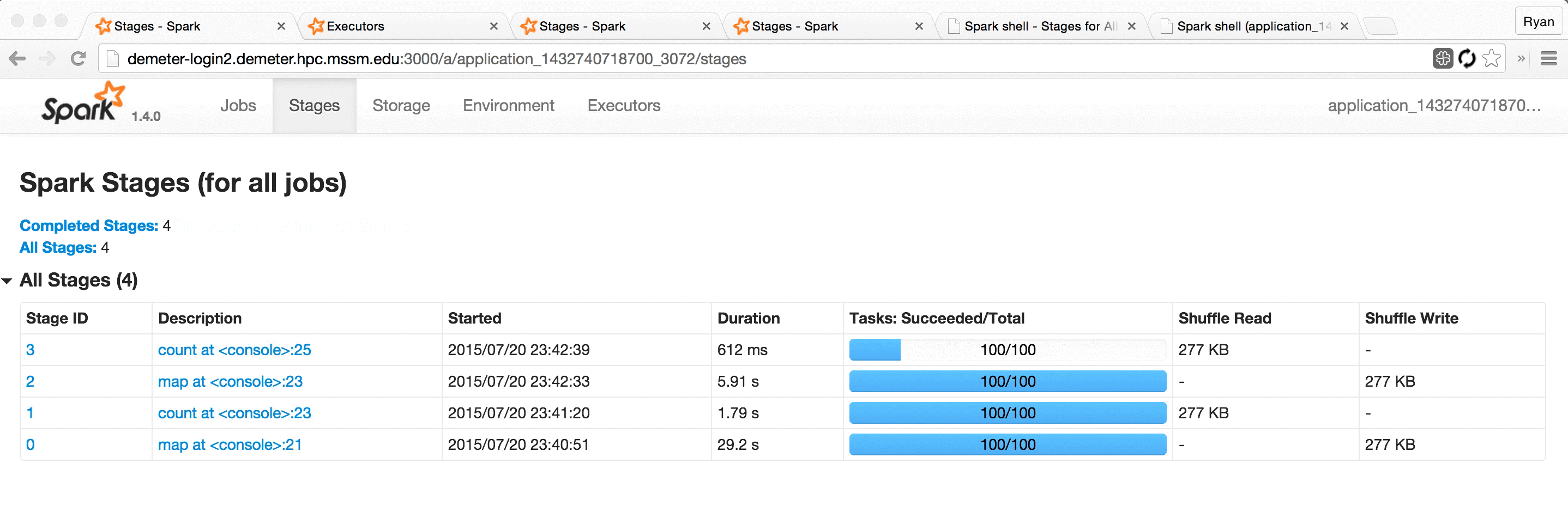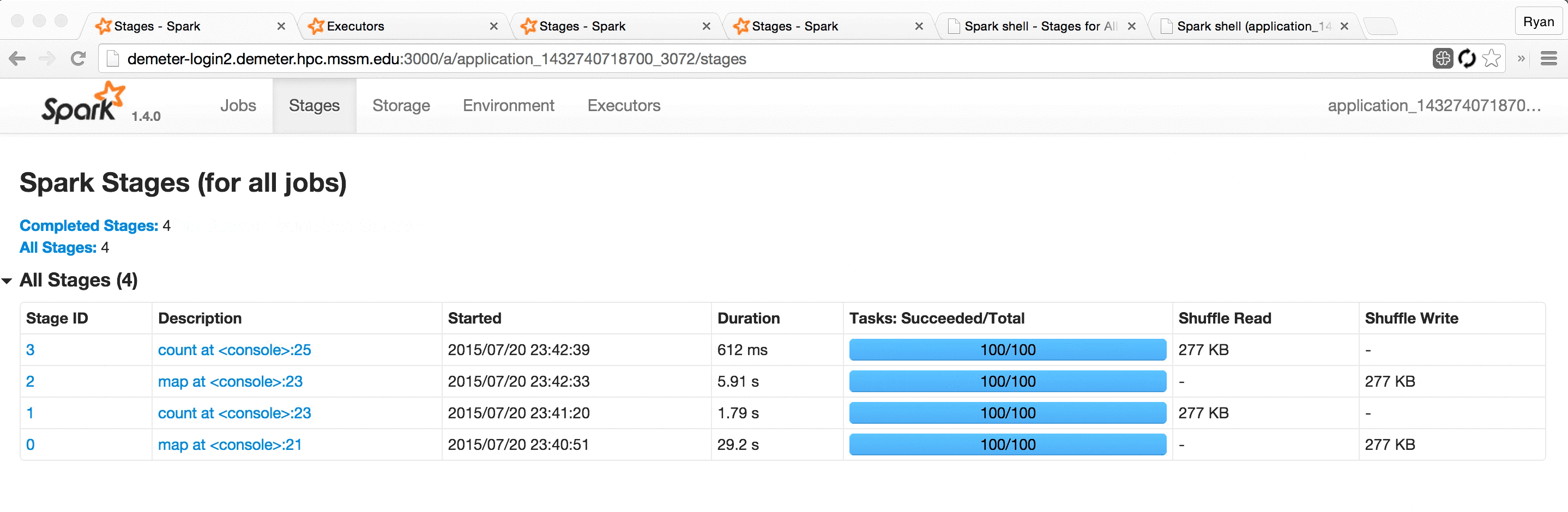 Screencast of Spree during a short Spark job
Screencast of Spree during a short Spark job
Spree looks almost identical to the existing Spark UI, but is in fact a complete rewrite that displays the state of Spark applications in real-time.
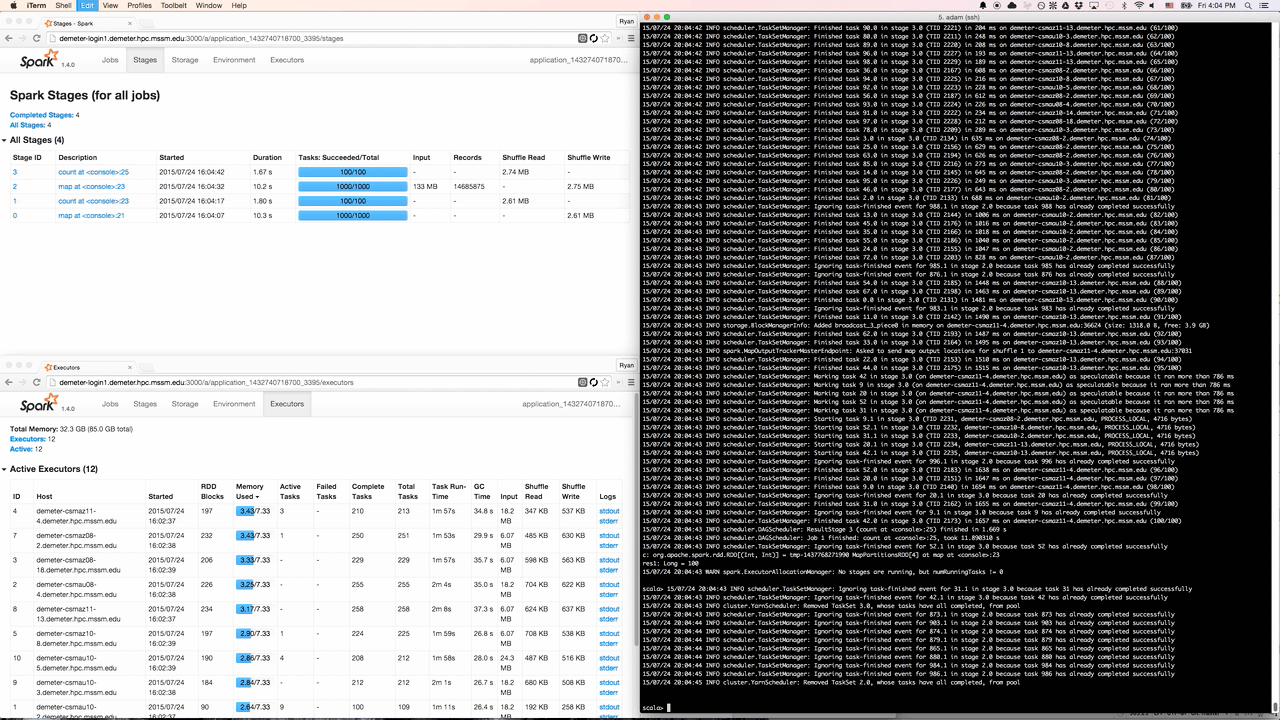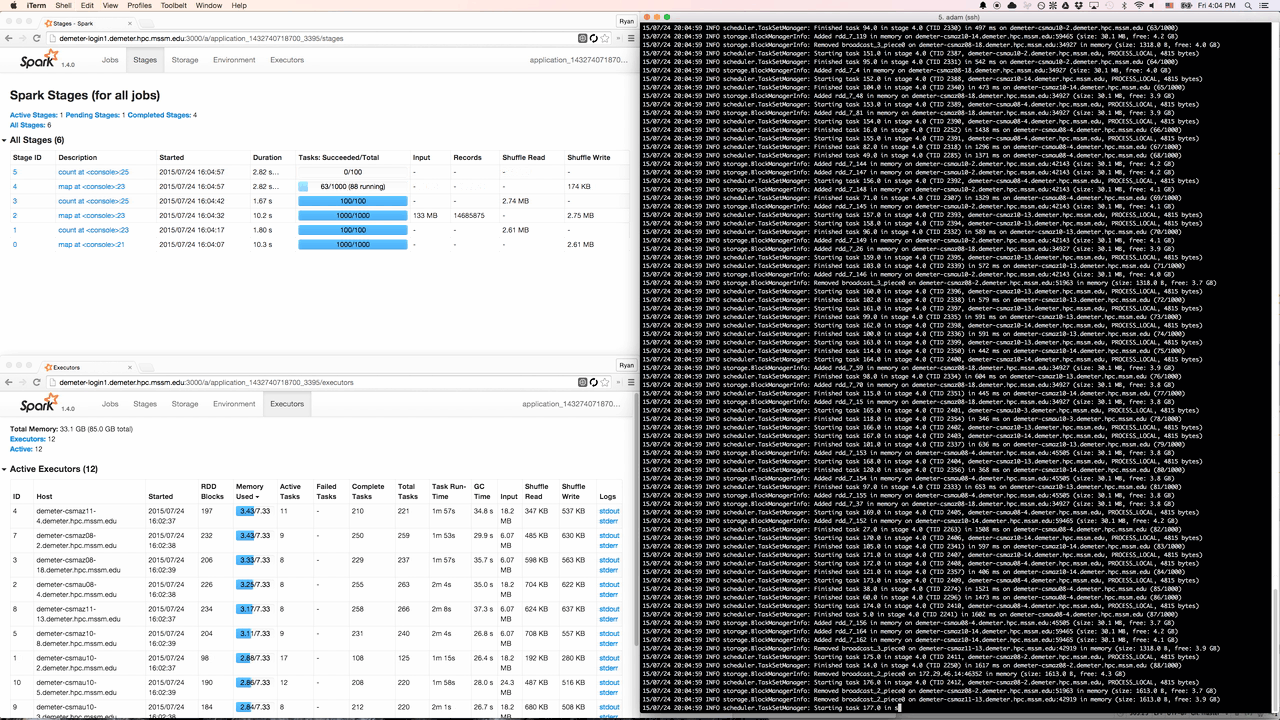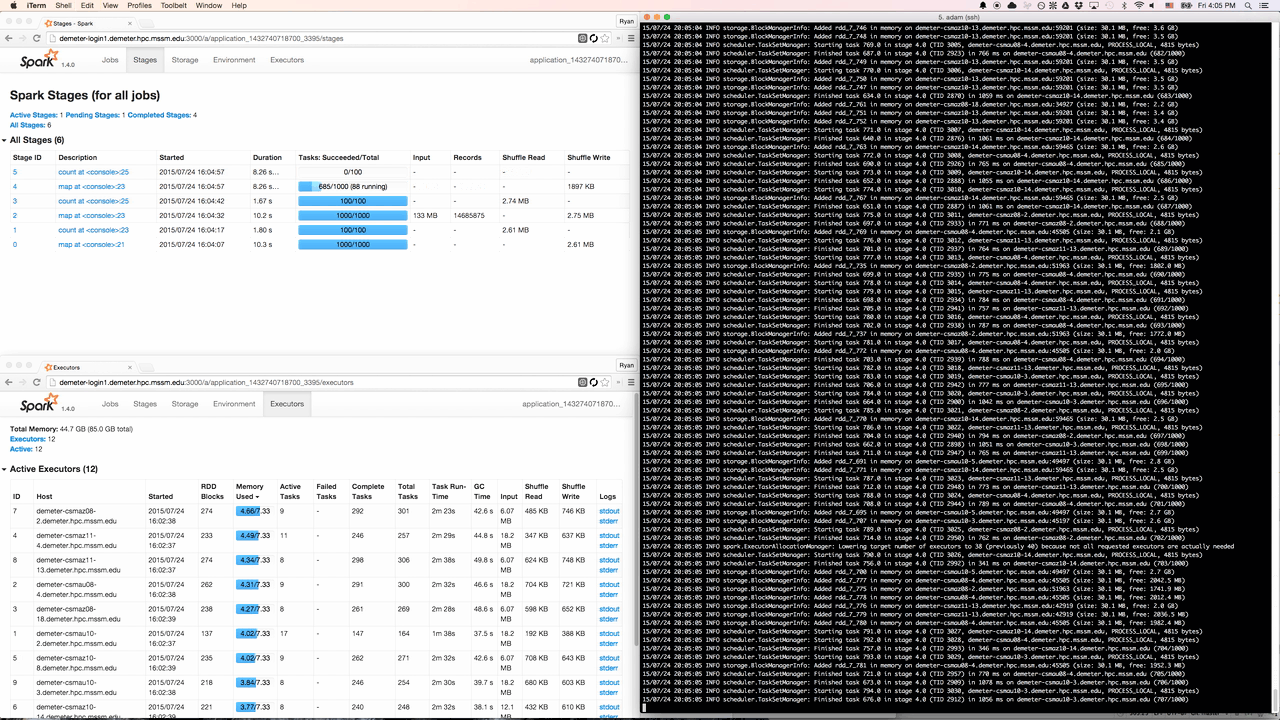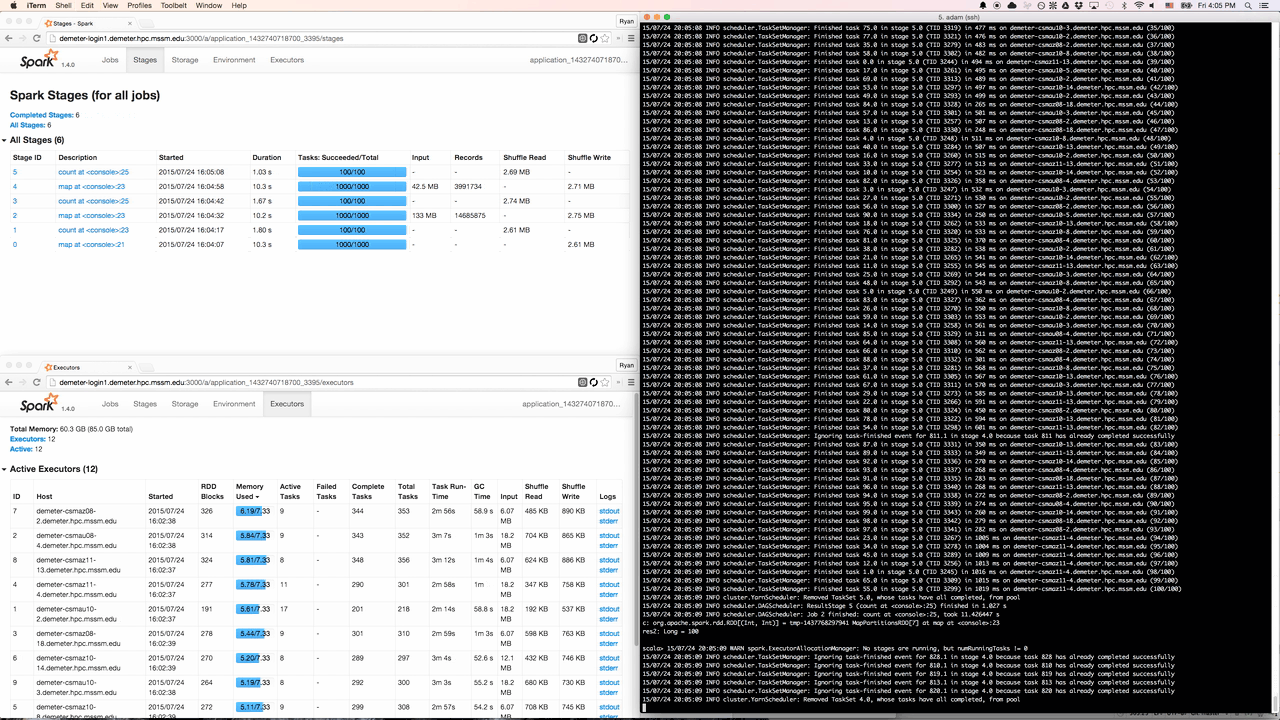 Spree displaying stages, executors, and the driver’s stdout in a terminal window
Spree displaying stages, executors, and the driver’s stdout in a terminal window
In this post we’ll discuss the infrastructure that makes this possible. If you’re just interested in using Spree right away, head on over to the Github repo for lots of information on getting started!
What Have We Built?
Several components are involved in getting data about all the internal workings of a Spark application to your browser:
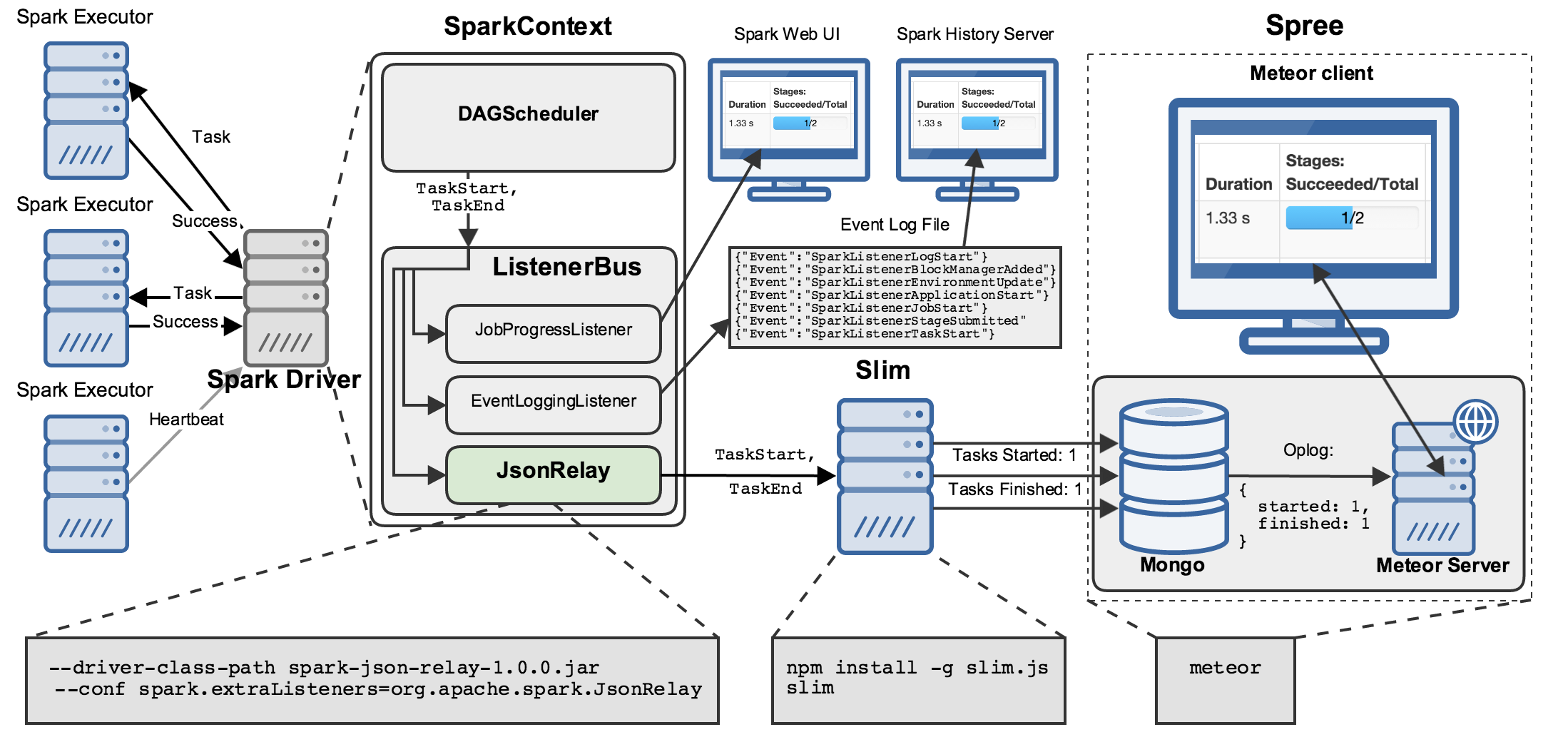
There’s a lot going on here, so let’s walk through this diagram step by step.
Basic Spark Components
At a high level, a running Spark application has one driver process talking to many executor processes, sending them work to do and collecting the results of that work:
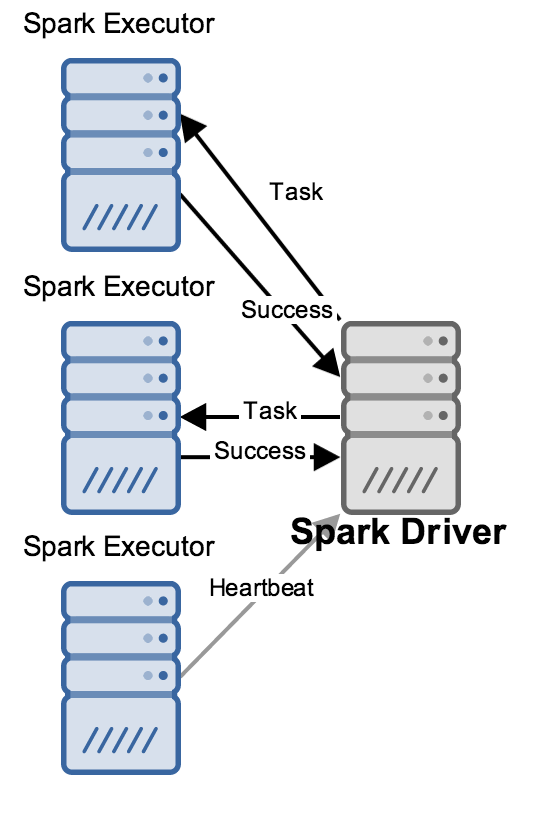
While this is happening, the driver is performing many bookkeeping tasks to maintain an accurate picture about the state of the world, decide what work should be done next where, etc. Two of its components in particular are relevant to this discussion: the DAGScheduler and the ListenerBus:
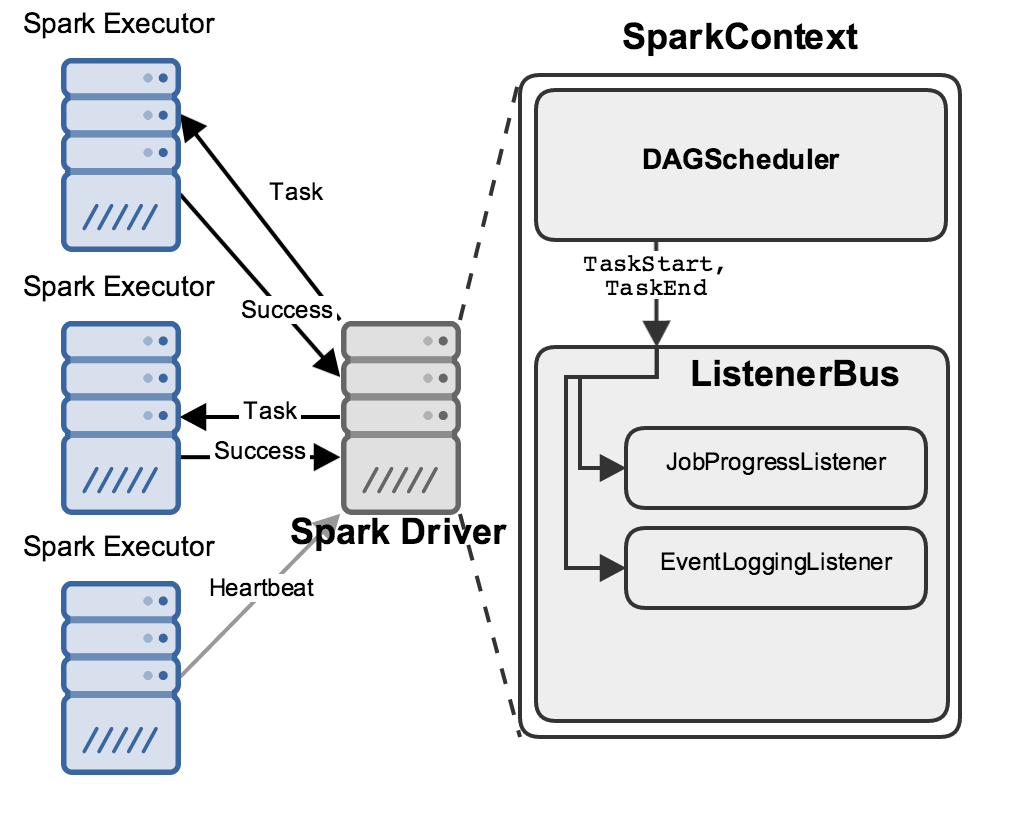
When anything interesting happens, like a Task starting or ending, the DAGScheduler sends an event describing it to the ListenerBus, which passes it to several “Listeners”.
Here I’ve shown two important listeners: the JobProgressListener and the EventLoggingListener; the former maintains statistics about jobs’ progress (how many stages have started? how many tasks have finished?), while the latter writes all events to a file as JSON:
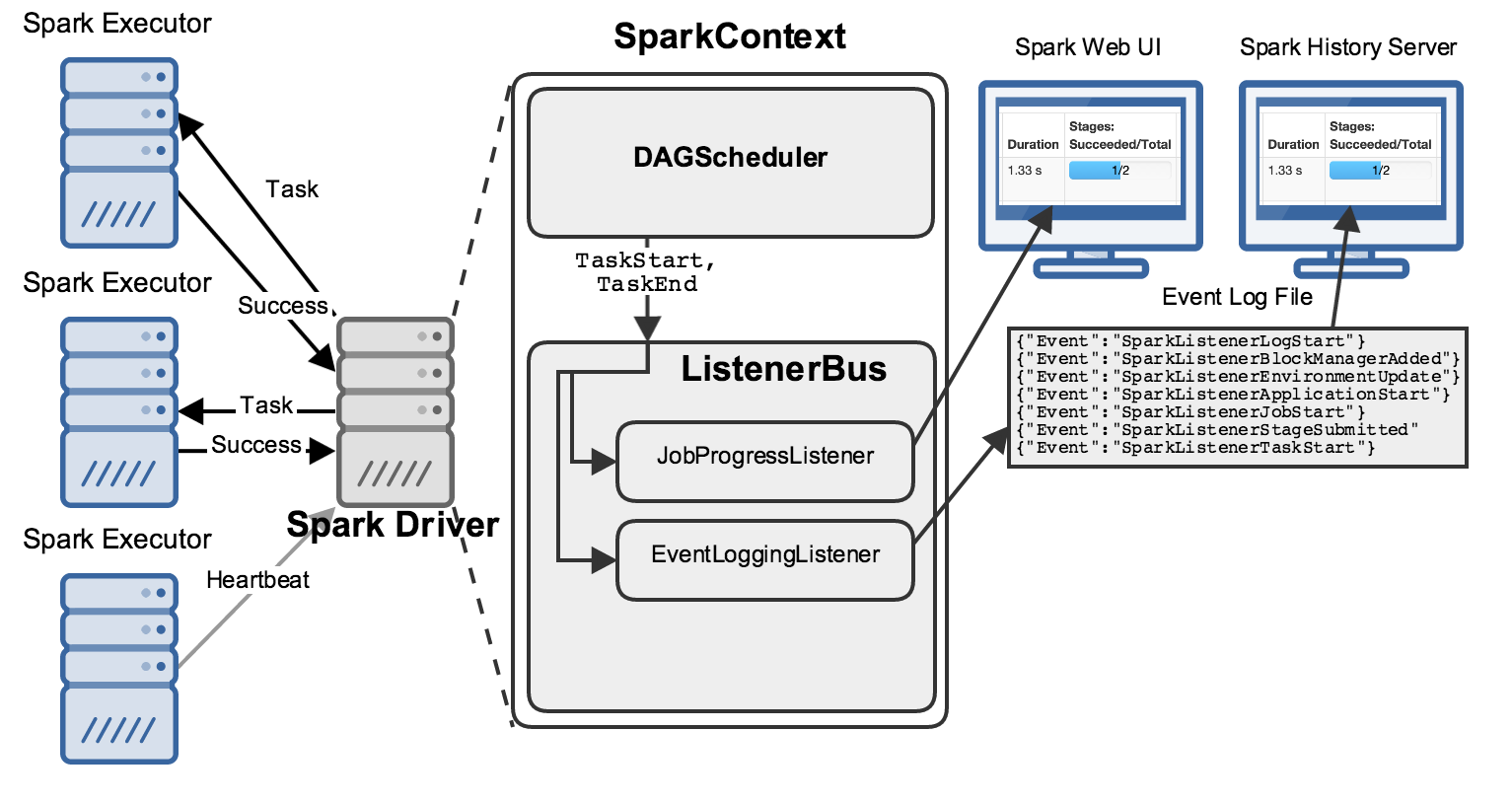
These listeners each power a web UI that you can use to learn about your Spark applications’ progress:
- Present: a “live” web UI exists only while a Spark application is running, and is fed by the stats accumulated by the
JobProgressListener. - Past: the Spark “history server” can be run as a separate process that ingests all of the textual JSON written by the
EventLoggingListenerand shows you information about Spark applications you’ve run in the past.
This works pretty well, but leaves a few things to be desired:
- Running separate processes to view “present” vs. “past” applications can be a bit clumsy.
- Using large text files full of JSON events as archival storage / an ad-hoc database creates problems, including causing the history server to be slow to start.
Listeners that ship with Spark and run in the driver are one-size-fits-all: customizing them to individuals’ needs is not really feasible.- Additionally, everything that runs in the driver must keep a very low profile so as not to bog things down.
So, our first step in innovating on Spark’s data-export, -storage, and -display landscape was to get the data out!
JsonRelay
We do this by registering our own listener, called JsonRelay:
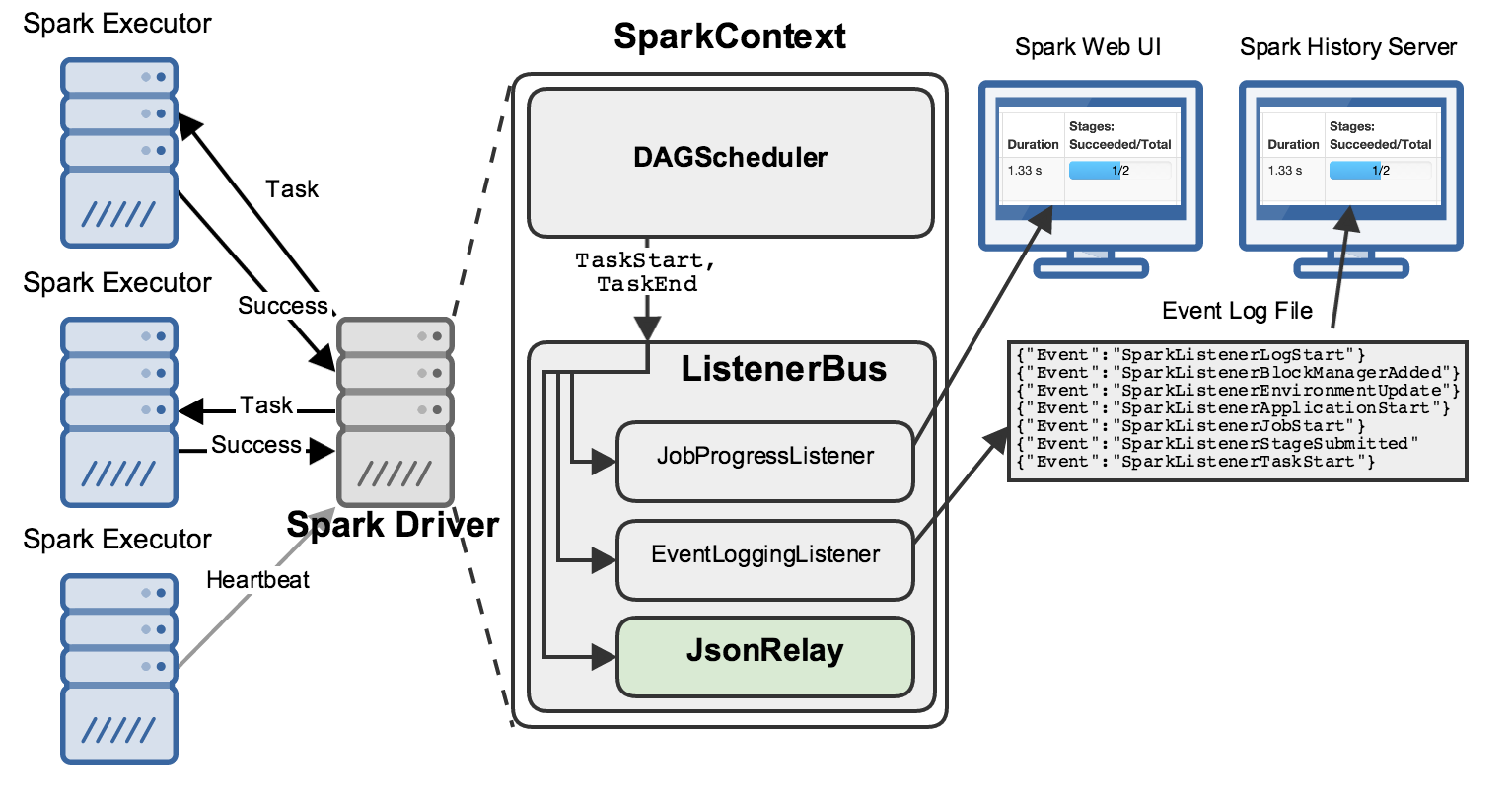
It is enabled by passing two command-line arguments to Spark, and will relay all events to a network address of your choosing.
slim
In our case, that address belongs to “slim”, a Node server that collects SparkListenerEvents and writes them to a Mongo database:
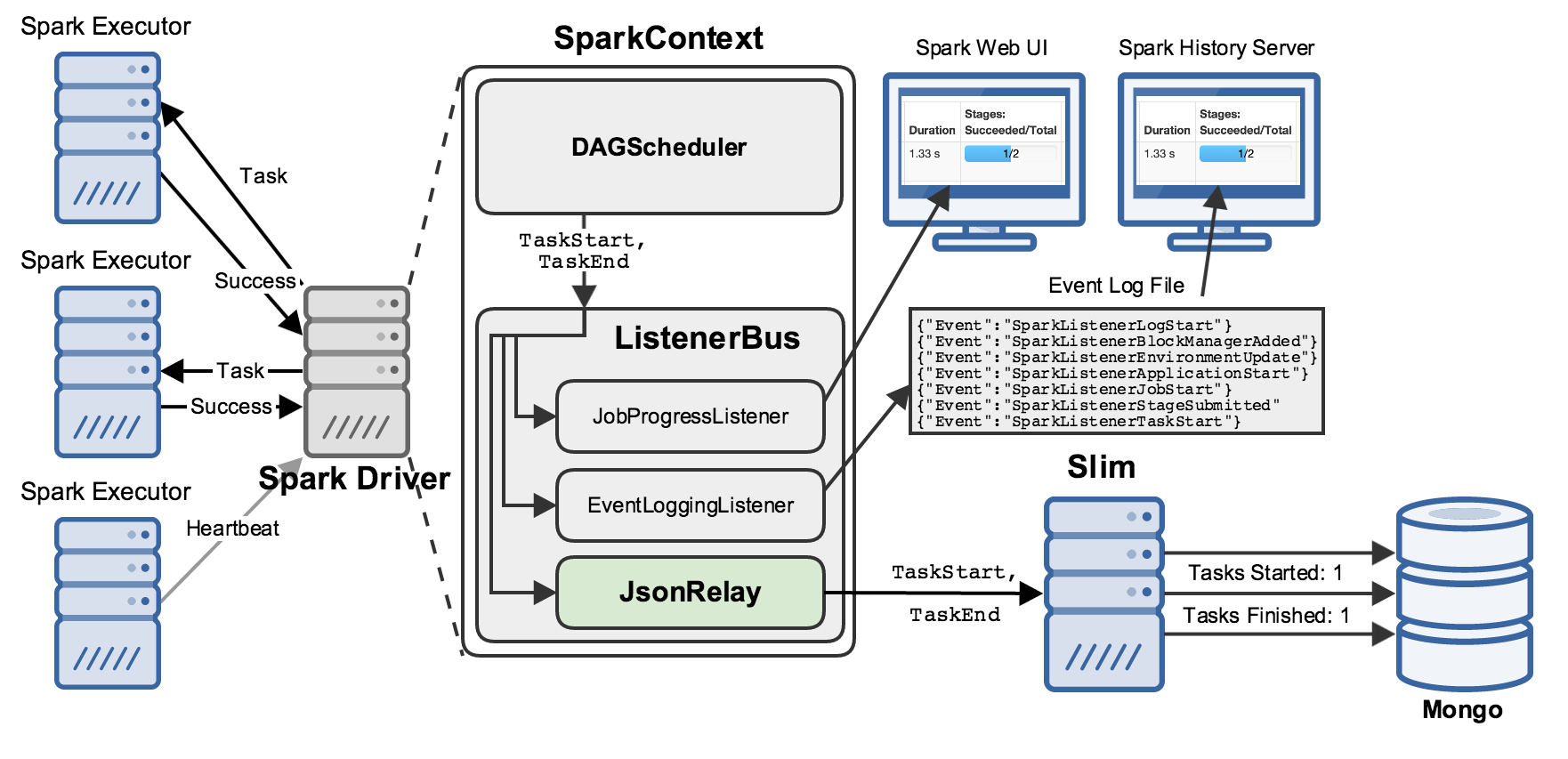
slim combines some of the best attributes of the JobProgress and EventLogging listeners:
- It maintains state about all the relevant objects in a running Spark application (jobs, stages, tasks, RDDs, etc.).
- It persists that state to Mongo, realizing the myriad benefits of using a proper database for archival storage, e.g. easy querying and retrieval by downstream processes.
JsonRelay and slim taken together represent a powerful tool for storing and retrieving information about Spark applications, and we hope that others will find it useful for a variety of purposes.
For us, however, the impetus for building them was…
Spree
Spree is the final piece of this puzzle: a web application that displays, in real-time, the data stored in Mongo by slim:
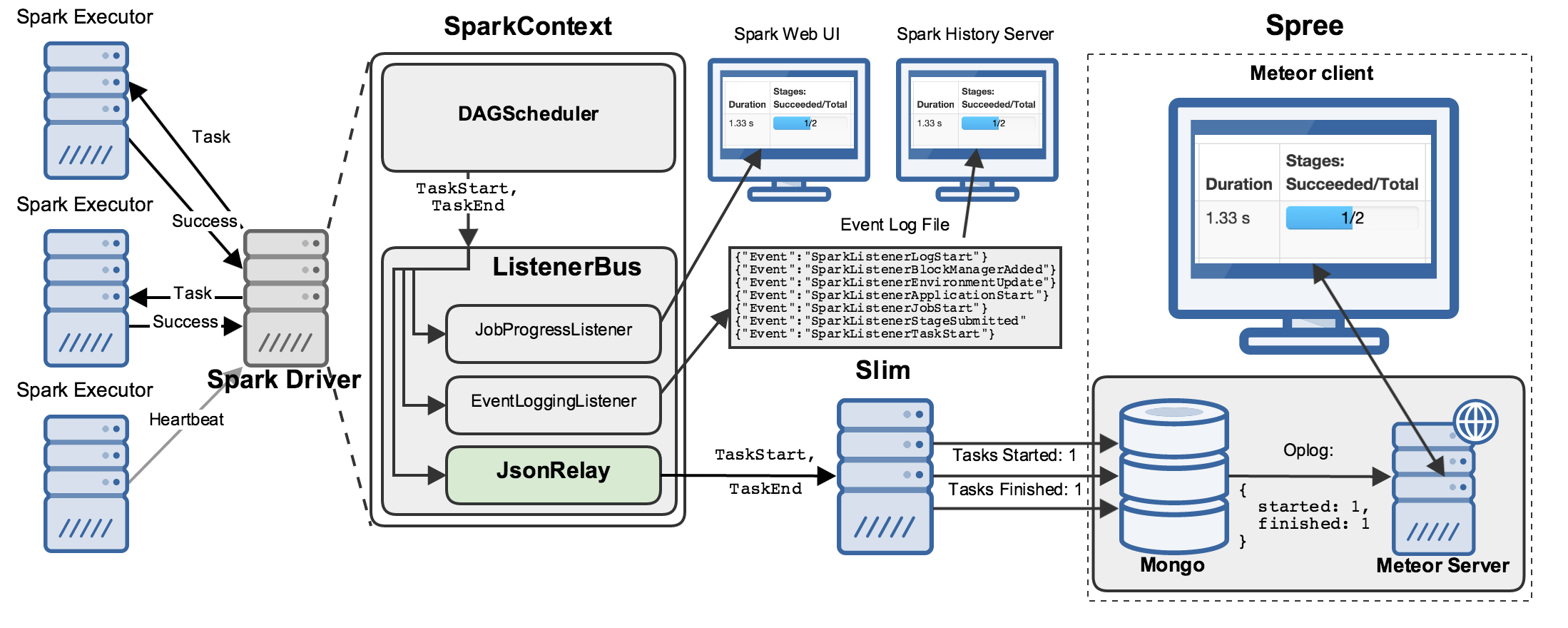
Getting data from Mongo through a server process to your web browser sounds complicated, but it is handled pretty magically by Meteor, a reactive web framework that powers Spree. Meteor provides powerful abstractions for adding this sort of “transparent reactivity” to applications of all shapes and sizes.
In particular, Meteor includes client- and server- Mongo libraries that speak to each other via Distributed Data Protocol (DDP), allowing web pages to subscribe to specific sets of records that they care about and thereafter receive updates from the server about them whenever they’ve changed. The Meteor docs on these tools are well worth a read, as they are in the process of being expanded to support additional popular backends and frontends and promise to increasingly be a great way to build web- and mobile-applications going forward.
Meteor… plus React
One particularly fortuitous recent development was Meteor’s release of a shiny new library for supporting React as a frontend to Meteor’s reactive-glue and back-end abstractions.
At the time of that announcement, Spree was facing issues re-rendering its pages’ DOMs in an efficient manner as deluges of events flooded in; pulling 100s of events per second off a web-socket is no sweat, but re-rendering large DOMs in response to each one was proving impossible.
Luckily for us, the React+Meteor integration deftly leverages React’s clever minimal-DOM-updating logic and Meteor’s declarative+reactive-UI functionality to make for an application-development experience that is unprecedentedly powerful.
Path Forward
Spree’s real-time display of our Spark jobs has been a boon to us, making the task of running multiple and long-running Spark jobs more painless, saving our ⌘R-fingers and freeing us from the tyranny of infinite auto-refresh!
{kind=link}
Combined with the ability to dump our Spark events into a database, keep past and present data in one (easily query-able) place, and quickly iterate on what we collect, store, and display, Spree (and friends) represent significant improvements to our experience using Spark that we hope others can benefit from.
The documentation for Spree and slim both go into a lot more detail about installing and using these tools, the relationships between them, and functionality added by or missing from Spree relative to the existing Spark UI; please give them a try and let us know in the issues there if you run into any problems!
As a parting gift, here is Spree running in Chrome on a Nexus 6, for when you just have to monitor your Spark jobs on the go 😀:
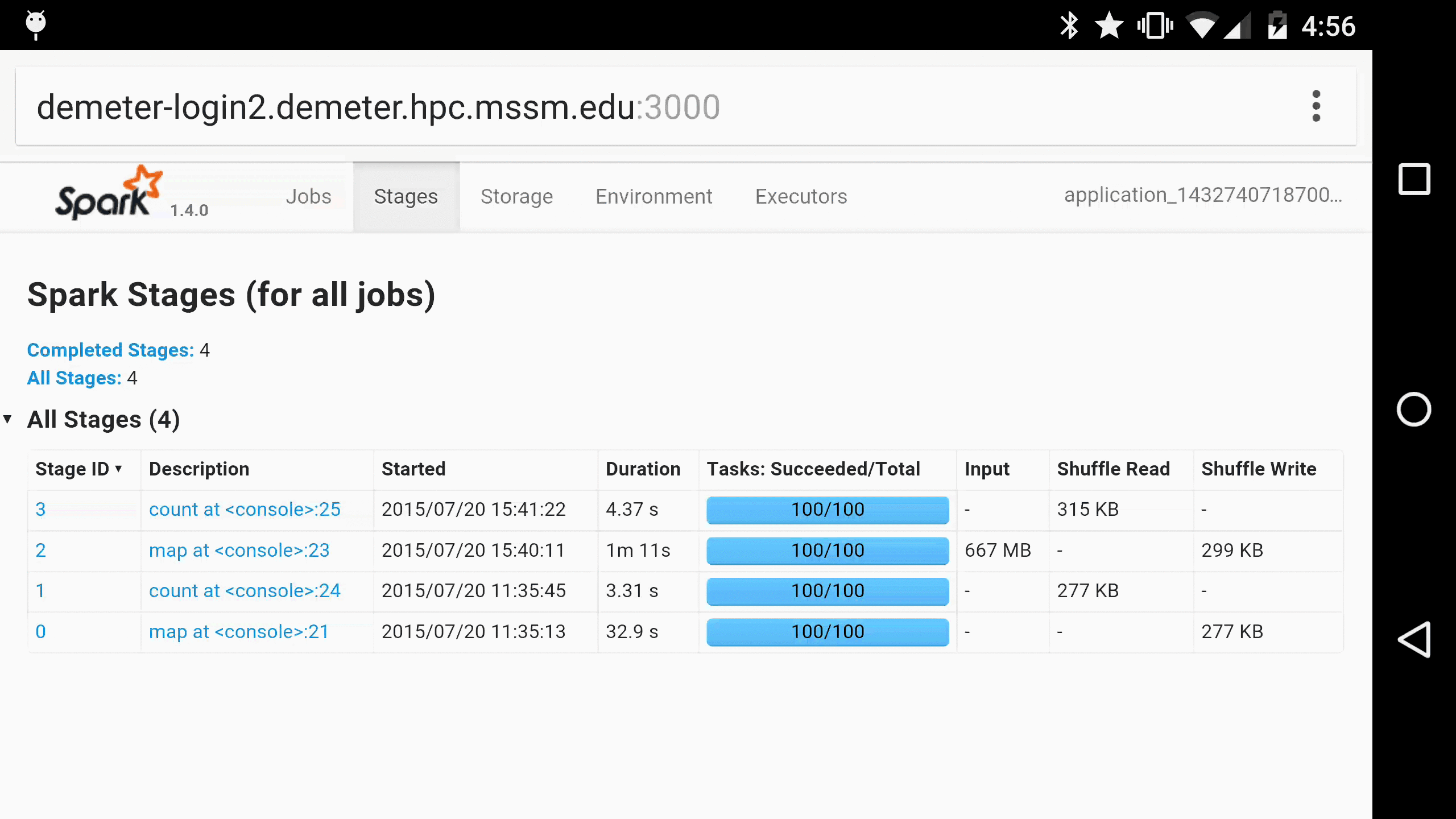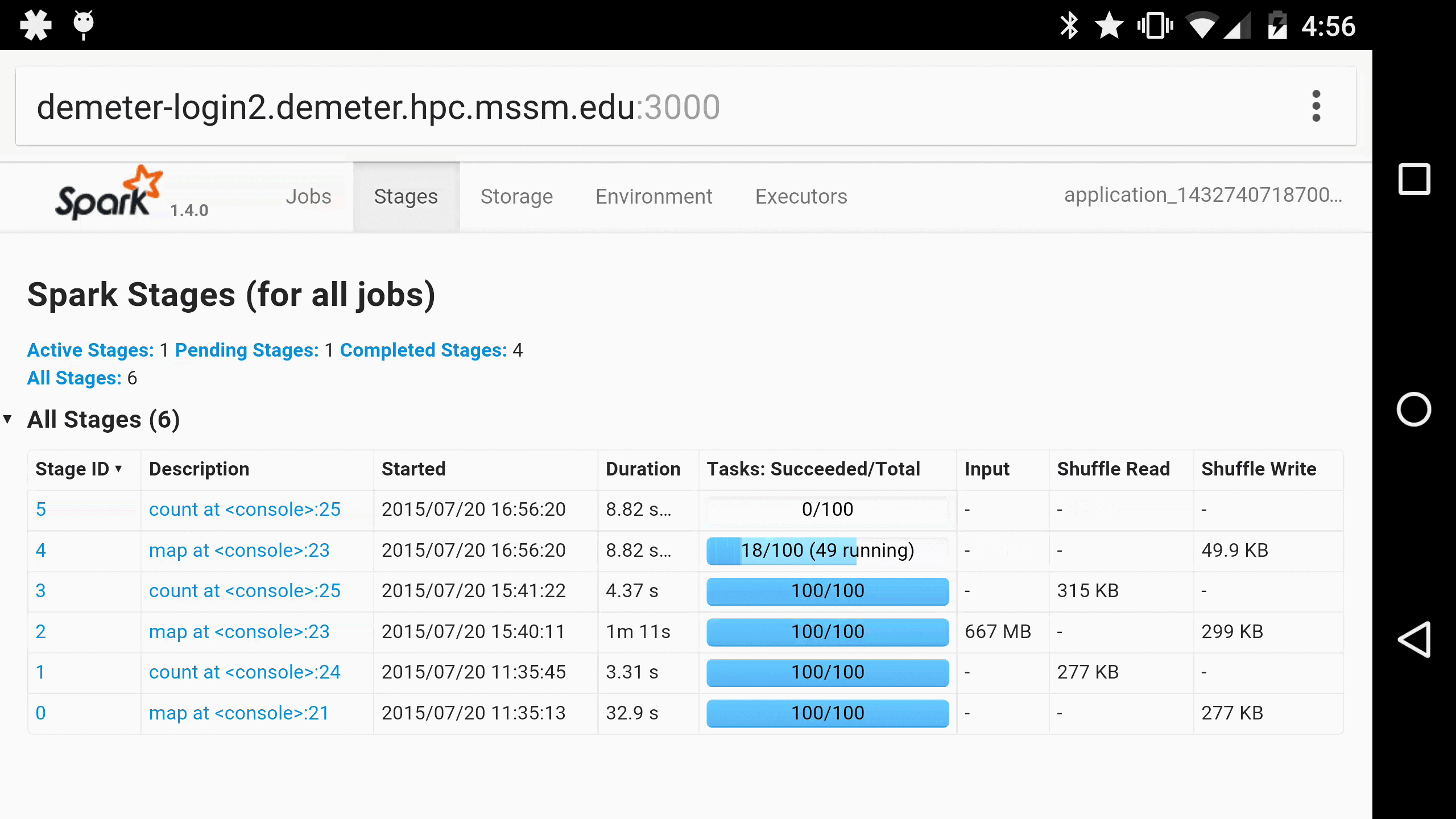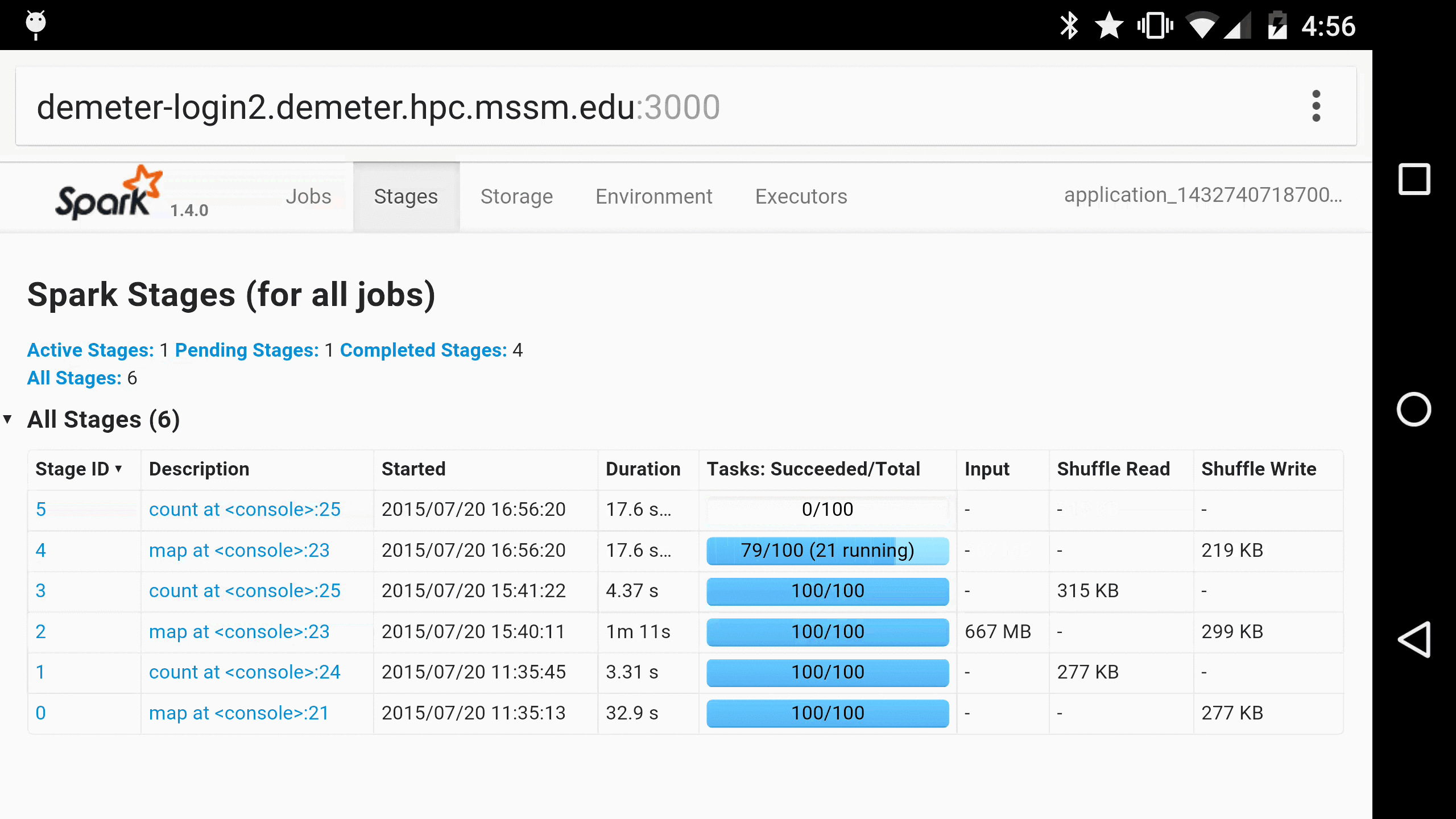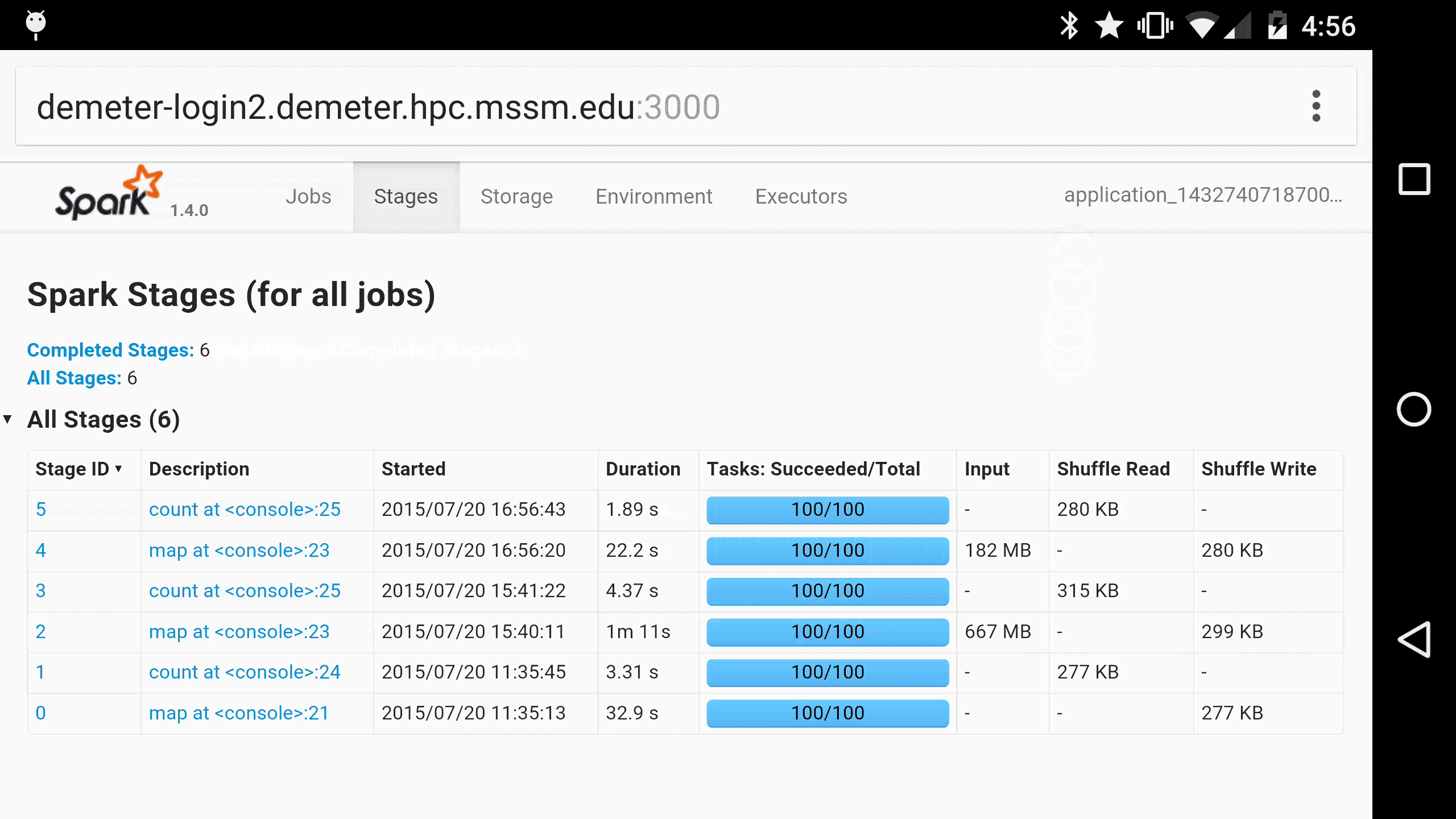
More gifs can be found in Spree’s screencast gallery. Enjoy!