
Building Scala Projects: Maven vs. SBT
06 Apr 2017 | by Ryan WilliamsOutline
- tl;dr: build logic is app logic
- Motivating example: releasing artifacts for multiple Scala versions
- SBT
- Conclusion
- Appendix
I’ve worked in Scala for 6 years on projects ranging in size from 100s to 100k’s of LoC and built with SBT, Pants, and Maven.
I recently surveyed the current state of these three tools and concluded that SBT is better suited than Maven to Scala projects’ needs.
The following is a discussion of the {theoretical,practical} ⅹ {pros,cons} of each.
tl;dr: build logic is app logic
Build/Package/Release logic is complicated, and deserves sophisticated tools and abstractions just as much as the code it builds.
Scala for project’s source ⟹ Scala for project’s build
There are many reasons that projects use Scala over other lanuages:
- type-system sophistication,
- crucial syntactic sugars,
- inheritance and implicits to taste,
- operator-overloading enabling eDSL-creation,
- etc.
All these reasons also favor configuring projects’ builds in Scala, as SBT allows, instead of in Python (Pants) or Java+XML (Maven); in many cases, increased expressiveness and safety is more important when configuring build workflows than when writing business-logic-heavy application code!
Java ⟶ XML ⟶ Bash… considered harmful
Instead, prominent Scala projects’ Maven builds are shoehorned into logic-less XML APIs presented by Java-bean-based plugins, which:
- sacrifice expressive power,
- fail to support essential tasks, and
- invariably rely on
bash-spaghetti in ascripts-dir to fill functionality gaps.
Such a complete encapsulation failure would never be tolerated in projects’ source, yet it is ubiquitous in Maven+Scala projects’ builds.
Motivating example: releasing artifacts for multiple Scala versions
A glaring problem in the Maven-builds of two projects I’ve used and worked on for years, Spark and ADAM, motivated this investigation.
Each releases _2.10 and _2.11 versions of several modules (e.g. spark-core_2.1{0,1}, adam-core_2.1{0,1}).
They do this by running a shell-script to toggle the current Scala version in the project between 2.10 and 2.11:
dev/change-scala-version.shin Spark,scripts/move_to_scala_2.1*.shin ADAM.
Maven-controlled release-processes are run in between applications of these scripts.
Regexing POMs
In each case, the shell-script uses sed to comb a regular expression over all pom.xml files in the repository, rewriting instances of 2.10 to 2.11 or vice-versa (and carefully excepting some hits, in ADAM’s case).
Spark’s release flow temporarily rewrites the POM to use Scala 2.10, releases that, then discards those changes, releases 2.11, and git tags that tree, leaving a git history like:

In ADAM, the POM changes are made into small _2.10- or _2.11-specific branches, each anchored by a git tag, which becomes the canonical SCM-pointer to each release:
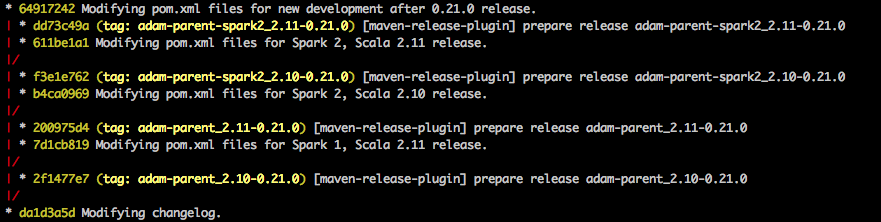
As you can see, a second, nested round of POM-regexing also happens (move_to_spark_2.sh) in order to publish for different Spark major-versions as well.
This is a bad state of affairs
Both of these workflows are distressing for several reasons:
- “Parsing” XML witih regexs is a famously bad/sloppy thing to do.
- The XML-“parsing” in question is not integrated with Maven at all.
- It resorts to
bashscripts, which fork tosed, despite its projects’ otherwise-deep buy-in to Maven’s project-management abstractions. - Further pipelining/automation of release-processes are pushed to the lowest-common-denominator workflow-management tool, which is now
bash.
- It resorts to
Spark is one of the biggest, most popular, and most active Apache projects; what hope do run-of-the-mill Scala projects have if this is the best release-workflow they can come up with?
Should people copy such a script into every Scala project they create?
It’s contagious
A little googling implies that Scala projects are, in fact, copying versions of this script around:
- here it is in Apache Zeppelin (2300+ GitHub stars),
- here in an Eclipse Foundation project called geomesa (200+ stars),
- here in Apache Bahir (80+ stars),
- here in Apache Flink (1800+ stars),
- bonus: script contains many regex-exceptions, and lives alongside a small zoo of similar POM-regexing shell-scripts,
… the list seems to go on.
Presumably there is a better way…
Maven provides a deep set of abstractions for designing build-scapes:
- projects are configured entirely through Project Object Model (POM) XML files,
- a rich ecosystem of plugins supports XML-specification of ≈any workflow one may desire, and
- an opinionated set of default “phases”, “goals”, and “plugins” are added to projects by default.
I assumed this framework would allow me to express a trivial modification (s/_2\.10/_2\.11/g) to one of the basic POM attributes (<artifact/>; <version/> would also suffice), but I was wrong.
2000 Spoons
I attempted to make this work in Maven in myriad ways:
- Nest a property (e.g.
${scala.version.prefix}) in the<artifact/>tag, similarly to how most Scala-binary-version-dependent dependencies are expressed. - Nest a property in the
<version/>tag, similarly to the above. - Override either tag inside a
<profile/>. - Define either tag in terms of an environment variable.
- Use
versions-maven-pluginto rewrite either tag.- Upgrade/fork
versions-maven-pluginto be able to rewrite either tag.
- Upgrade/fork
- Write a Maven plugin from scratch for this purpose.
- Create a
<profile/>that invokesversions-maven-pluginfollowed by other build/release tasks, the latter ideally operating on a module whose artifact/version had been changed. - Make the project’s root a POM-only parent-module (i.e.
<packaging>pom</packaging>), and then add JAR-packaged sub-modules for the_2.10and_2.11artifacts. - (Mis)Use
maven-release-pluginand/ormaven-deploy-pluginto override what artifact/version are released (according to some user-supplied configuration, e.g. a profile or property). - Use classifiers, per a suggestion on this Spark dev list discussion.
All of these approaches failed.
Some discussion of specific failure-modes – and a sketch of an idea for actually accomplishing this with Maven – can be found in Appendix A, but suffice it to say that after being blocked in so many novel and frustrating ways from accomplishing something so simple, I began evaluating alternatives to Maven for my Scala-project-management needs.
SBT
SBT makes cross-publishing artifacts for different Scala versions trivial: you put a + in front of a task on the CLI, and it runs for all Scala-versions you’ve configured the project to build against.
For example:
sbt +publishSigned sonatypeRelease
builds JARs, POMs, source- and javadoc-JARs, and tests-JARs if desired (with corresponding sources- and javadoc-JARs), each for arbitrary Scala-binary-versions, and publishes the lot to Maven Central.
Beyond cross-publishing
While SBT clearly went out of its way to make cross-publishing trivial, the added power from configuring builds in Scala has also proved invaluable.
In short order I ported several dozen Scala projects to SBT, factoring out all repeated build-configuration to hammerlab/sbt-parent along the way; my plan is now to use SBT for all Scala projects for the forseeable future, and recommend that others do the same.
Below I’ll drill in on specific pros and cons:
The Good
SBT gets several crucial things right:
“Key-value”-style configuration is succinct and sufficient in common cases
Consider this example from hammerlab/genomic-utils, setting a few project-level fields:
organization := "org.hammerlab.genomics"
name := "utils"
version := "1.2.0"
An equivalent pom.xml block would look like:
<groupId>org.hammerlab.genomics</groupId>
<artifactId>utils</artifactId>
<version>1.2.0</version>
which is comparably verbose.
In reality, the POM would have more boilerplate above and below this just supporting these values, and considerably more when expressing the remaining project configuration:
deps += libs.value('htsjdk) // add a dependency, referenced by a name declared in the parent plugin
addSparkDeps // add dependencies on Spark, Kryo, and a test-scoped dependency on hammerlab/spark-tests
publishTestJar // publish a "-tests" JAR, and attendant -sources and -javadoc JARs
The point is: Scala code can be made at least as lean for expressing simple attributes as any markup-language.
Where necessary, advanced language features can be deployed, and blocks factored out and reused
hammerlab/sbt-parent includes implementations of many repeated configuration blocks that have been factored out for concise re-use across projects.
Some examples in the wild:
- cross-publish for different Spark major-versions by setting
-DsparkXon the command-line- injects
_spark1,_spark2, or neither into the artifact-ID, depending on the project’s defaultsparkVersionand whether-Dspark1or-Dspark2was passed.
- injects
- shade Guava dependency
- add Scala 2.12 to the cross-publishing list.
- only publish for Scala 2.11
- disable cross-publishing altogether
- publish an
-assemblyJAR - publish a
-testsJAR (and corresponding-sourcesand-javadocJARs) - include “hidden” files as test-resources (excluded by default)
- add specific dependencies as
compile-scoped, and their-tests-JAR astest-scoped
Many more such conveniences can be found in the build.sbts of the modules in hammerlab/spark-genomics and by reading the hammerlab/sbt-parent implementation.
Plugin ecosystem parity with Maven
There seem to be functional plugins for all important tasks from the Maven ecosystem:
- releasing,
- Sonatype-interfacing,
- applying code-style checks,
- interfacing with code-coverage tools,
- performing shading/assembly tasks,
- etc.
In some areas, SBT plugins exist that go beyond what I’ve observed to be possible in the Maven world, e.g. sbt-pack’s one-step creation of tarballs that can be make installed.
The Bad
In 2017, SBT is a lot more usable than at points in the past, but its learning curve remains steep. Some notes on classes of issues I hit:
Inscrutable and poorly-documented abstractions
SBT decomposes work into “tasks”, “settings” (special-cases of tasks), and “commands”; how/whether to compose/combine any of the three with any of the others, including themselves, is remarkably hard to understand.
- Tasks and settings can reference other tasks and settings using the
.valuemember, except that settings can not reference tasks. - Commands can access settings’ values using a
.gimmemethod/hack borrowed from the sbt-coveralls plugin;- requires in-scope
implicitvalues of three other mystery-noun-types: - …wat
- requires in-scope
- Commands can run tasks using
Project.runTask. - Commands can run other commands using
Command.process.
However, even within this characterization there are some incorrect assumptions and caveats warranted, so a bit of feeling around in the dark is still inevitable when attempting any nontrivial pipelining.
The code is almost completely uncommented
A gem of SBT’s design is a lazily-eval’d computation-dependency-graph compiled statically from tasks’ references to other tasks/settings, using some macro-magic associated with a .value method on settings and keys.
As far as I can tell no one has tried to discuss how/why this works in a way that is remotely accessible to a non-SBT-committer.
This SO answer is the only discussion of it I’ve seen anywhere (incidentally, also linked to by sbt-coverage’s .gimme implementation above).
Ivy resolution
SBT uses a “latest wins” heuristic for resolving conflicting versions of dependencies: the newest version of a library found in the dependency tree will be used.
Maven, on the other hand, uses a “nearest wins” strategy: versions declared by dependencies closer to the root of the dependency tree are favored.
This discrepancy can lead to unexpected problems moving between Maven and SBT, or maintaining parallel builds; see this related configuration in Spark’s SBT build, and discussion on this example repo and in the SBT Gitter room.
The Gitter
In some low moments I was able to get help in the SBT Gitter room, particularly from @dwijnand (thanks! 😀).
Among other things, he recommended this excellent blog post as a starting point for understanding SBT’s design/API, which was very helpful.
Conclusion
Doing away with the daily indignities of trying to serialize simple build-logic into Maven’s uncooperative POM framework has been a boon to my ability to create, release, and maintain Scala projects, and I hope that my travelogue here will help others in similar situations.
Realizing that I wanted/needed as much from language/tooling when configuring my builds as I do when writing the code that I later seek to build was an important epiphany, and has led to further revelations about missing functionality in the larger JVM-ecosystem-project-management universe, that I hope to touch on in subsequent posts.
Feel free to drop by any of the hammerlab-org repos linked here, or our public slack channel, to discuss further!
Appendix
A: Trying and Failing to Scala-cross-publish with Maven
The following are notes on a couple of attempts to set up a Maven-based workflow for cross-publishing differing Scala-binary-versioned artifacts:
Rewriting POMs
Several things I explored involved rewriting POMs, like a change-scala-version.sh does, but perhaps with a real XML parser or in a way that is somehow better-integrated with other Maven workflows.
At the end of the day I found this approach to be suboptimal at a high level: Maven only picks up POM-changes when a new invocation is run, and this feels like a basic breach of the dependency-/worfklow-management contract.
In any case, here are some such attempts that were nevertheless unworkable:
Using versions-maven-plugin
This plugin is in wide use for doing things sort of like what is required for cross-publishing Scala-binary-versioned artifacts, but on investigation I found it to not facilitate much improvement over the status quo.
Its Maven phase parses the POM XML, rewrites the appropriate <version/> tag(s) (with… fake XPaths?), and then writes the POM back out, taking care to preserve whitespace and any POM-formatting idiosyncracies. Subsequent mvn-CLI invocations then pick up the values in the rewritten POM.
That sounds like an improvement, but would basically require two actions to run:
- rewriting
<artifact/>, using a new function similar to ones inPOMHelper - updating the
${scala.binary.version}property typically used for qualifying dependencies.
Digging in, I found that the plugin adds some overhead to this (values it splices in must be versions of dependencies that it is aware of), and the end-result would still be an unsatisfying rewrite-the-POM-then-run-again state of affairs, so I gave up on this approach.
Using maven-release-plugin
Like versions-maven-plugin, this plugin is used for similar POM manipulations to those we might desire, e.g. rewriting a bunch of <version/> tags using an XML parser.
Also like versions-maven-plugin, unfortunately, its operations are only picked up by subsequent Maven invocations, which breaks the .
BYOPlugin
I prototyped a custom Maven plugin for doing POM rewrites similar to those discussed above, but was stymied; for one, I wanted to write my plugin in Scala, but this generated the kind of errors (and corresponding empty SERPs) that made me feel that no one had ever attempted as much before, and that it wasn’t likely to be workable.
As also mentioned above, I was also pursuing the “POM-rewriting” approach, not appreciating that what I really wanted was an altogether different model, discussed below.
Coloring inside the lines
A couple of approaches sought to use existing Maven-plugin XML APIs to do what I want; they also failed!
hammerlab/scala-parent-pom: factor out the boilerplate
I thought I might solve cross-publishing by having a POM for each Scala-binary-version I wanted to publish for, and a parent POM that wrapped 2.10 and 2.11 submodules.
Of course, almost everything would be reused in both modules’ POMs, so you’d want most things (like <dependencies/>) specified in the parent.
However, I ran aground: some ${scala.version.prefix} had to be set in the parent-POM that was published, and the child/implementation modules inevitably inherited whatever was set there: I was back to needing to cross-publish the parent POM, or repeat all dependencies in each child POM.
vanzin/multi-scala
In discussion of an early draft of this post, @vanzin pointed me to this attempt at solving this problem, which is used in production by cloudera/livy.
At the time of this writing, my understanding is that it faces the same problem described above, per vanzin/multi-scala#1.
Maven <classifier/>s
AFAICT, classifiers can’t be made to solve this, because Scala 2.10 and 2.11 releases require not just JARs with different names and binary contents, but different dependencies as specified in the POM; this seems to require separate POMs, and therefore separate (group,artifact,version) tuples.
“If I knew then what I know now”
I think that one could write a Maven plugin that, instead of rewriting POMs and requiring a Maven reboot, used APIs like MavenProject.setArtifactId to modify internal Maven state that would govern how all of its usual phases operated.
You could then have a <profile/> – ideally defined in a parent-POM that Scala projects inherited, to minimize boilerplate – that activated a custom plugin phase that changed the <artifact/> and <${scala.binary.version}/> before proceeding through all requested phases, without messing with transient POM changes or Maven reboots.
B: Pants
As mentioned at the start of the post, I also experimented with porting some repos to Pants.
Pants’ design has some desirable properties over all other tools that I’m aware of:
- explicit tracking and caching of workflow-nodes’ inputs and outputs,
- support for caching outputs globally (e.g. across an organization),
- automatic analysis/pruning of dependencies,
- etc.
However, the open-source community / support-base around it is significantly smaller than that of Maven and SBT, and it felt like I’d have to write some plugins myself, in Python, which proved to be a dealbreaker given the option to write build logic in Scala instead.
I hope some of the great features of Pants will become more accessible soon, or that other tools will incorporate them!