
Kubeface: distributed computing in Python on Google Container Engine
18 May 2017 | by Tim O'DonnellThis post introduces a Python library called Kubeface for parallel computing on Google Container Engine using Kubernetes. We developed Kubeface to train the neural networks we publish in the MHCflurry package. There's nothing specific to neural networks in Kubeface, however, and we've used it to run a variety of compute-bound, easily-parallelized tasks.
Outline
Container engine background
Similar to Amazon Web Services (AWS) Elastic Compute Cloud, Google Compute Engine makes it easy to start and stop virtual machines, but leaves it to other systems to manage the deployment of jobs or services on these machines. Google Container Engine (GKE) addresses this need. It's a hosted deployment of Kubernetes, an open source project that grew out of Google infrastructure. Given a description of a service — for example, "run 5 database servers and 10 web servers" — Kubernetes starts, stops, and monitors the execution of docker images on Compute Engine instances to keep the service running.
Thanks to infrastructure support from the Parker Institute for Cancer Immunotherapy, we've been experimenting with Google Cloud as a platform for scientific computing.
Workload
Our neural network model selection task is an embarassingly-parallel problem in which we wish to train and evaluate a large of number neural network architectures. Each architecture evaluation runs on a single node. The data sizes are modest, at most a few gigabytes per model, but evaluating each model takes up to a few hours.
The table below shows the approximate design parameters for the jobs we need to run.
| Cluster size | 10-200 nodes (16-64 processors per node) |
| Simultaneously running tasks | ~200 |
| Time per task | 1 minute to 10 hours |
| Input size per task | < 2 gb |
| Output size per task | < 2 gb |
| Total tasks | 100 - 50,000 |
| Total time per job | 10 min - 10 days |
Existing solutions
In early experiments with Kubernetes, we quickly realized that some sort of layer between our application code and Kubernetes is required, as the the Kubernetes interface is too low-level and failure-prone to use directly as a job scheduler.
There are a number of projects in the Python ecosystem for farming out long-running tasks to remote workers, such as celery, dask.distributed, ipyparallel, and ray. On AWS, the PiCloud project was once popular but is no longer maintained. A recently developed package called PyWren that targets AWS Lambda looks promising, but is geared toward short-running jobs (300 seconds or less).
We initially experimented with celery (as described in this blog post) and dask.distributed to train our neural networks. With much-appreciated help from Matthew Rocklin, the author of dask.distributed, we succeeded in training the models released with MHCflurry 0.0.8 on GKE using this approach (see here for our configuration).
Systems like celery and dask.distributed have an architecture centered on persistent worker processes running on the worker nodes. The master dispatches tasks to the workers using a message queue (celery) or via a special scheduler process (dask). This approach has major advantages. Scheduled work can begin to run almost immediately, efficient inter-node communication patterns may be implemented, and the system is agnostic to the infrastructure used to start the workers (and is in fact a good fit for the service-oriented Kubernetes).
On the other hand, since the workers survive between tasks, state changed by one task can affect subsequent tasks in unforeseen ways, for example by creating temporary files that fill up the worker's disk. If a failure occurs, it can be unclear whether the problem is due to the master node, the scheduler, the worker node, or even a previous task run by the worker node. Debugging systems with distributed state and peer-to-peer communication is notoriously difficult. These packages also require a deployment process to launch the workers on the cluster. Each of our workloads require specific libraries installed in the Docker image, so we found ourselves starting and stopping deployments of dask.distributed workers frequently.
A simpler approach
A potentially better solution in our case is to schedule work directly on Kubernetes. We don't care about latency: in a multi-hour batch computation, it's fine if it takes a minute or two for a task to start running. While Kubernetes is designed for long running services, it provides some support for the sort of batch jobs that are common to scientific computing. We therefore came up with an approach in which tasks run in their own Kubernetes pods and all communication is done through Google Storage Buckets (the Google equivalent to Amazon's S3).
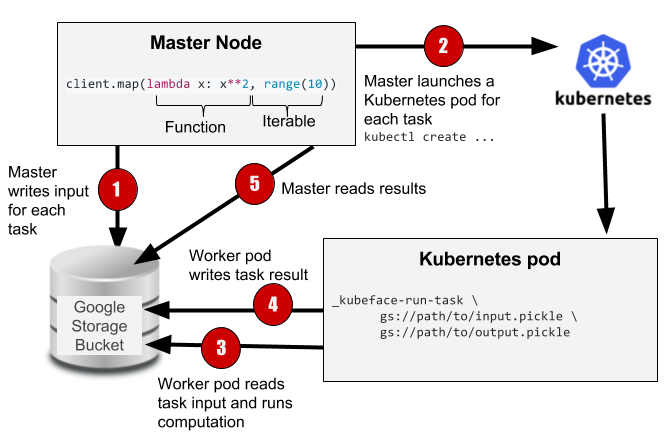
The Kubeface API is a parallel map. Kubeface invokes a function on each element in an iterable and returns the results. Each function invocation is called a task. As shown in the diagram, the Kubeface "master" process, i.e. the program the user runs, copies the input data for each task to the storage bucket. It then instructs Kubernetes to run pods that read the input data from the bucket, run the computation, and write the result to the bucket. The master process waits for the tasks to run and then reads the results from the bucket.
At the cost of some scheduling latency due to running a fresh Kubernetes pod for each task, as well increased I/O because we are moving data using a storage bucket instead of directly between nodes, we have a much simpler system. Tasks are isolated from each other, and a failing task may be debugged locally by invoking the Docker image. GKE supports auto-scaling clusters so we use only the instances we need. Importantly, the state of the distributed computation is simply the contents of the storage bucket. This simplifies debugging and also makes it straightforward to implement two useful Kubeface features: reuse of completed tasks when rerunning a failed job and speculative rerunning of straggling or failed tasks.
What’s next
We've used Kubeface to run several hundred jobs over the past three months, including MHCflurry model training and large analyses of the human proteome. While the system is increasingly reliable, debuggable, and performant we’ve hit plenty of issues. On the GKE side, we were surprised to find Kubernetes and Google Storage Buckets prone to transient service outages. Anywhere that Kubeface interfaces with these systems we've implemented a wait-and-retry policy. As Kubernetes seems to fail if we schedule more than 400 or so simultaneously running tasks, Kubeface must limit the number of tasks queued at once (we typically set the limit to 200). Kubernetes also loses the logs of pods frequently.
Aside from issues with GKE, the current Kubeface implementation itself leaves room for improvement. Most significantly, the Kubeface master does not track the progress of a task. It simply issues a call to Kubernetes to launch the task and then watches the storage bucket for the task's result to appear. A small number of task failures can be tolerated since speculation will cause dead tasks to be rerun eventually, but if a large number of tasks fail, the job will hang. It would be better to interface more tightly with Kubernetes and expose the status (e.g. pending, running, failed) to the master node. There are also a number of things we could do to improve the user experience, such as a more usable job status page and better handling of logs. In the longer term, it would be nice to support other Kubernetes deployments besides GKE, such as Kubernetes on Amazon EC2.
Kubeface is still early stage software, but we welcome anyone who would like to use or develop it further with us, as well as suggestions for better approaches. If you give it a try, check in and let us know how it goes!